Load_Balancing
LoadBalancing
Load balancing (Server Load Balance) means to balance and distribute the load (work tasks) to multiple operating units for execution, so that the entire system can complete the task together.
Load balancing provides a cheap and effective method to expand the bandwidth of network devices and servers, increase throughput, enhance network data processing capabilities, and improve network flexibility and availability. According to the different implementation purposes of load balancing, load balancing can be divided into two types. One is task sharing, in which a large amount of concurrent access or data traffic is shared among multiple devices for separate processing, and each device completes a relatively complete request response process; the other is collaborative computing, which shares a heavy-load computing task. Perform parallel processing on multiple devices. After each device completes processing, the results are summarized and calculated.
As mentioned above, the key to load balancing is to enable the task load to be carried as evenly as possible on the servers in the cluster to avoid the situation where some servers in the cluster are overloaded and other servers are idle. In a cluster that implements load balancing, multiple servers are connected together through the network. By deploying a load balancing device at the front end of the cluster, user requests are distributed in the cluster according to the preconfigured balancing strategy and the availability of the server is maintained. The schematic diagram of load balancing implementation is shown below.
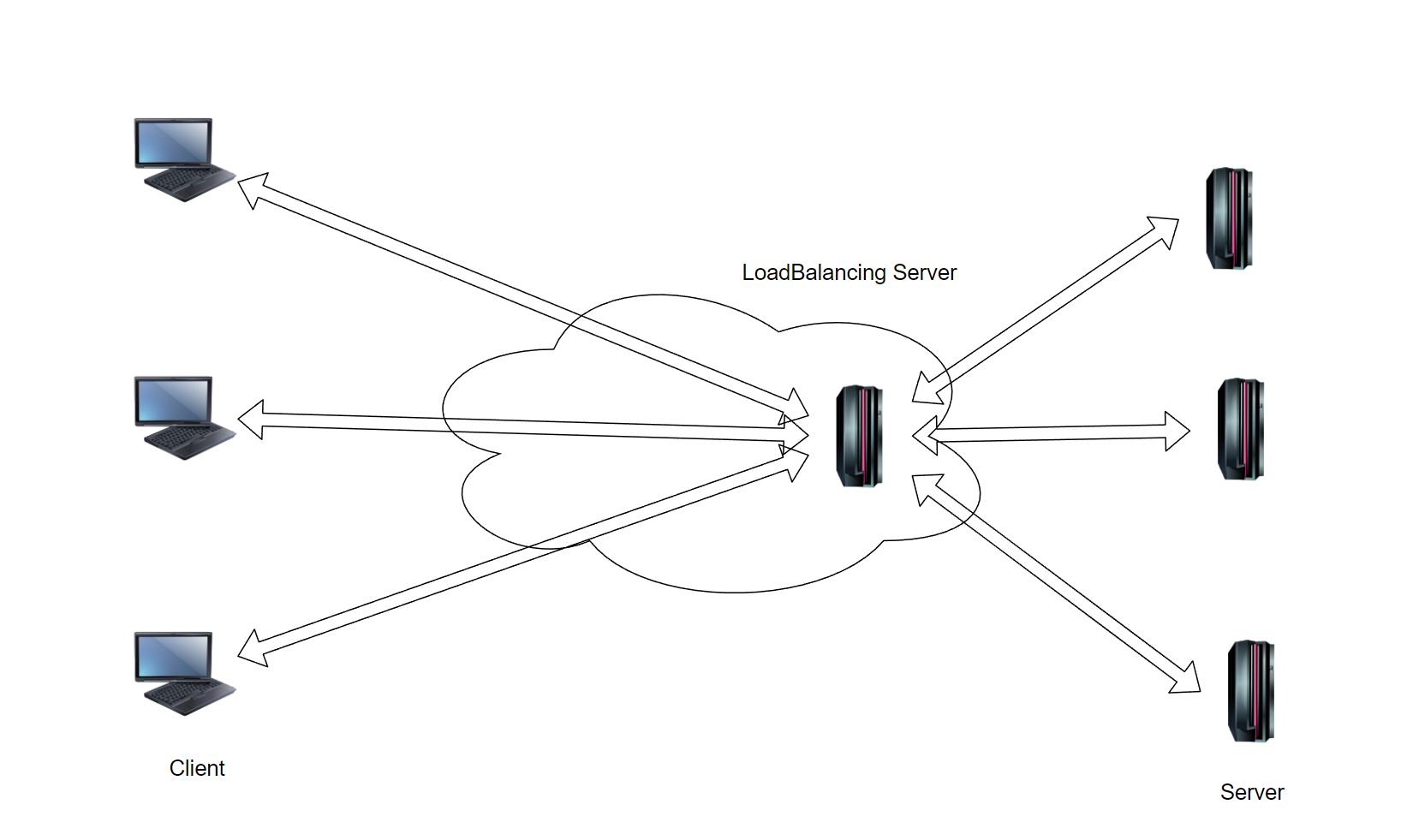
As can be seen from above figure, the load balancing device can intercept user requests from the client before the server, and then distribute them to the appropriate backend servers according to the preconfigured load balancing policy. Therefore, the service request message sent by the client must first be sent to the IP address of the load balancing device. Because this address is not responsible for processing actual business operations, this address is usually called a virtual IP address, and the backend is called the virtual IP address. A real business server is called a real server. The load balancing device communicates with the client through the virtual IP address, and then reasonably distributes the load to the real server.
For a long time, load balancing was mainly carried out on the fourth layer of the OSI seven-layer network protocol stack. With the increasing variety of business types, the continuous improvement of user refinement requirements and the great improvement of in-depth analysis technology, based on Layer 7 load balancing technology has gradually become mainstream.
Key technologies of load balancing
The goal of load balancing is to reasonably distribute user requests to appropriate servers to achieve the optimal solution for system processing. Its key technologies include: load balancing distribution, session persistence guarantee, server health detection, etc.
Load balancing scheduling algorithm
The goal of the load balancing scheduling algorithm is to efficiently and correctly distribute user requests and related traffic to servers in normal working status, so that each server can maintain load balancing as much as possible.
At present, a very rich load balancing scheduling algorithm has been used in commercial systems. Generally speaking, scheduling algorithms can be divided into two categories: static algorithms and dynamic algorithms. The static algorithm refers to distribution according to a preset strategy without considering the actual load of the current server, and its implementation is relatively simple and fast. Typical static algorithms include polling, weighted polling, random, weighted random, source IP-based Hash, source IP port-based Hash, destination IP-based Hash, UDP message payload-based Hash, etc.; dynamic algorithms can be based on The connections are distributed according to the actual load conditions of each server, which has a better balancing effect. Typical dynamic algorithms include based on minimum connections, based on weighted minimum connections, minimum response time, etc.
Round Robin: Distribute requests to different servers in sequence, so that each server equally shares the user’s connection requests. This algorithm is suitable for scenarios where the performance of each server in the cluster is equivalent without obvious differences.
Weighted Round Robin: Distribute requests to different servers in sequence. Those with larger weights are assigned more requests, and those with smaller weights are assigned fewer requests. This algorithm uses weights to identify the distribution between servers. Performance differences are applicable to scenarios where performance varies between servers.
Random: Randomly distribute requests to different servers. From a statistical point of view, the scheduling result is that each server equally shares the user’s connection requests. This algorithm is suitable for servers in the cluster with equivalent performance. Scenarios with no obvious advantages or disadvantages.
Weighted Random: Randomly distribute requests to different servers. From a statistical point of view, the scheduling result is that each server shares the user’s connection request according to the weight ratio. This algorithm is suitable for clusters Scenarios where the performance of each server is different.
Hash based on source IP (Source IP Hashing): Use a Hash function to map requests from the same source IP address to a server. This algorithm is suitable for applications that need to ensure that requests from the same user are distributed to the same server. Server scenario.
Hash based on source IP port (Source IP and Source Port Hashing): Use a Hash function to map requests from the same source IP address and source port number to a server. This algorithm is suitable for requests that need to ensure that they come from the same source IP address and source port number. A scenario where user requests for the same business are distributed to the same server.
Hash based on destination IP (Destination IP Hashing): Use a Hash function to map requests to the same destination IP address to a server. This algorithm is suitable for ensuring that requests to the same destination are distributed to Scenario of the same server.
Hash based on UDP packet payload (UDP Packet Load Hashing): Requests with the same content in specific fields in the UDP packet payload are mapped to a server through a Hash function. This algorithm is suitable for applications that need to ensure that UDP packets have the same content. A scenario in which requests with the same specific field content in the text payload are distributed to the same server.
Least Connection: Estimate the load of the server based on the current number of connections to each server, and allocate new connections to the server with the smallest number of connections. This algorithm can reasonably distribute user requests with large differences in connection retention time to each server. It is suitable for scenarios where the performance of each server in the cluster is equivalent, there is no obvious difference in advantages and disadvantages, and the connection retention time initiated by different users has large differences. .
Weighted Least Connection: When scheduling new connections, try to make the number of active connections already established on the server proportional to the server weight, where the weight identifies the performance difference between servers. This algorithm is suitable for Scenarios where the performance of each server in the cluster is different, and the connection duration initiated by different users varies greatly.
Least Response Time: When scheduling new connections, try to choose a server with a short response time to user requests. This algorithm is suitable for scenarios where user requests require a high response time from the server.
Different scheduling algorithms achieve different load balancing effects, and different algorithms can be selected according to the needs of actual application scenarios. For example, the Web server cluster can use the polling algorithm to obtain a higher access response, the FTP server cluster can use the minimum connection algorithm to reduce the pressure on a single server, and the dedicated business clusters such as tax declaration can use the Hash algorithm based on the source IP port to ensure user access. Persistent.
In addition to the traditional distribution algorithms mentioned above, distribution algorithms for content analysis have received more and more attention from load balancing equipment manufacturers in recent years. For example, for a Web server cluster, the load balancing device used not only needs to be able to distribute HTTP traffic based on IP address and default port 80, but also needs to be distributed to designated servers based on HTTP headers or content. This type of device can analyze HTTP messages to obtain information such as Accept-Encoding, Accept-language, Host, Request-Method, URL-file, URL-function, User-agent, etc., and distribute it to the appropriate server based on this. ask.
Session continuity guarantee technology
The goal of session persistence guarantee technology is to ensure that the session between a certain user and the system is only handled by the same server within a certain period of time. This is particularly important when meeting the needs of application scenarios such as online banking and online shopping.
In actual applications, a business interaction may include multiple TCP connections, and TCP connections of different services have their own characteristics. For example, the FTP service connection includes a control channel and multiple data channels. There is an explicit correlation between these TCP connections, that is, the TCP connection of the data channel is negotiated through the control channel. Therefore, during the load balancing process, you only need to analyze the control channel messages of the FTP service to obtain the information of each data channel and then incorporate this information into a session to ensure that all channels access the same server. However, for the HTTP business, there is no such explicit correlation between its various TCP connections. As we have learned in Chapter 3, HTTP is a stateless protocol. However, in some scenarios, it is required to establish an association between a series of HTTP messages, such as HTTP online shopping. This can only rely on the relevant information carried in the data packet to express the association between connections, such as source IP address, cookie data, etc. .
The technology discussed here is that the load balancing device determines the server that handles the connection request by analyzing the implicit correlation existing in the four-layer TCP packets and the seven-layer HTTP messages, thereby achieving session persistence guarantee. The main ideas in this field include the following points.
Persistence maintenance based on source IP address: Mainly used for four-layer load balancing to ensure that services from the same source IP can be allocated to the same server. When the load balancing device receives the first request of a certain IP, it establishes a persistence entry and records the server status assigned to the IP. During the lifetime of the session entry, subsequent business packets with the same source IP address will be is sent to this server for processing.
Persistence maintenance based on cookie data: mainly used for seven-layer load balancing to ensure that packets of the same session can be distributed to the same server. Among them, depending on whether the server’s response message carries the Set-Cookie field containing server information, it can be divided into cookie insertion or cookie interception methods.
Cookie insertion and retention: The server’s response packet does not carry the Set-Cookie field containing server information, but the load balancing device adds relevant information to the packet. In this way, the client will add the Cookie field containing the server information to the request message, and then the load balancing device will send the request message to the corresponding server based on the server information in the Cookie field.
Cookie interception and retention: The server’s response message carries the Set-Cookie field containing server information. The load balancing device intercepts the Cookie value in the response message based on the cookie identifier configured by the user. For subsequent client request messages, if they match the cookie value stored in the load balancing device, the load balancing device will directly send the request message to the corresponding server.
Persistence maintenance based on SIP message Call-ID: Mainly used for Layer 7 load balancing to ensure that SIP messages with the same session ID in IP sessions can be distributed to the same server. When the load balancing device receives the first request for a certain service from a certain client, it establishes a persistence table entry and records the server status assigned to the client. During the lifetime of the session table entry, subsequent requests with the same session ID are All SIP service packets will be sent to this server for processing.
Persistence maintenance based on HTTP headers: Mainly used for seven-layer load balancing to ensure that packets with the same key information in HTTP headers can be distributed to the same server. When the load balancing device receives the first request for a certain service from a certain client, it establishes a persistence entry based on the HTTP header keyword and records the status of the server assigned to the client. During the lifetime of the session entry , subsequent messages with the same HTTP header information will be sent to the server for processing. As for what information is set as keywords, it is a step in configuring the load balancing policy.
Server health detection technology
The goal of server health detection technology is to promptly discover and eliminate servers that are not working properly and retain a “healthy” server pool to provide services to users. The core of server health detection is to regularly detect the working status of the server, collect corresponding information, and promptly isolate servers with abnormal working status. In addition, in addition to identifying whether the server can continue to work, the results of the health test can also calculate the response time of the server, which can be used as a basis for the load balancing device to select the server.
Currently, a lot of server health detection technologies have been used in the field of load balancing. The main method is to determine the health of the server by sending different types of protocol messages and checking whether the correct response can be received. The main methods include the following.
ICMP: Send an ICMP Echo message to the server in the cluster. If the ICMP Reply is received correctly, it proves that the server’s ICMP protocol is processed normally.
TCP: Initiate a TCP connection establishment request to a certain port of the server in the cluster. If the three-way handshake is successful to establish the TCP connection, it proves that the server TCP protocol is processed normally.
HTTP: Establish a TCP connection with the HTTP port of the server in the cluster (port 80 by default), and then issue an HTTP request. If the received HTTP response content is correct, it proves that the server HTTP protocol is processed normally.
FTP: Establish a TCP connection with the FTP port of the server in the cluster (port 21 by default), and then obtain the file on the server. If the content of the received file is correct, it proves that the server FTP protocol is processed normally.
DNS: Send a DNS request to the DNS server in the cluster. If a correct DNS resolution response is received, it proves that the server DNS protocol is processed normally.
RADIUS: Send a RADIUS authentication request to the server in the cluster. If a response of successful authentication is received, it proves that the server RADIUS protocol is processed normally.
SSL: Initiate an SSL connection establishment request to the server in the cluster. If the SSL connection is successfully established, it proves that the server SSL protocol is processed normally.
For different server functions, you can choose corresponding health detection methods. For example, ICMP detection is suitable for health detection at the server host level, TCP detection is suitable for health detection at the business level, and detection of HTTP and FTP is suitable for health detection at the application level.Once an abnormality in server processing is discovered, the load shared on it can be transferred to the appropriate “healthy” server through the load balancing mechanism to ensure the availability of the entire cluster system.
Load balancing deployment method
In specific implementation, load balancing equipment can be deployed in two ways: direct connection and side-mounted deployment. In addition, in order to improve network availability, dual-machine hot backup deployment of load balancing equipment is also necessary.
Common load balancing deployment methods
- Direct connection deployment method
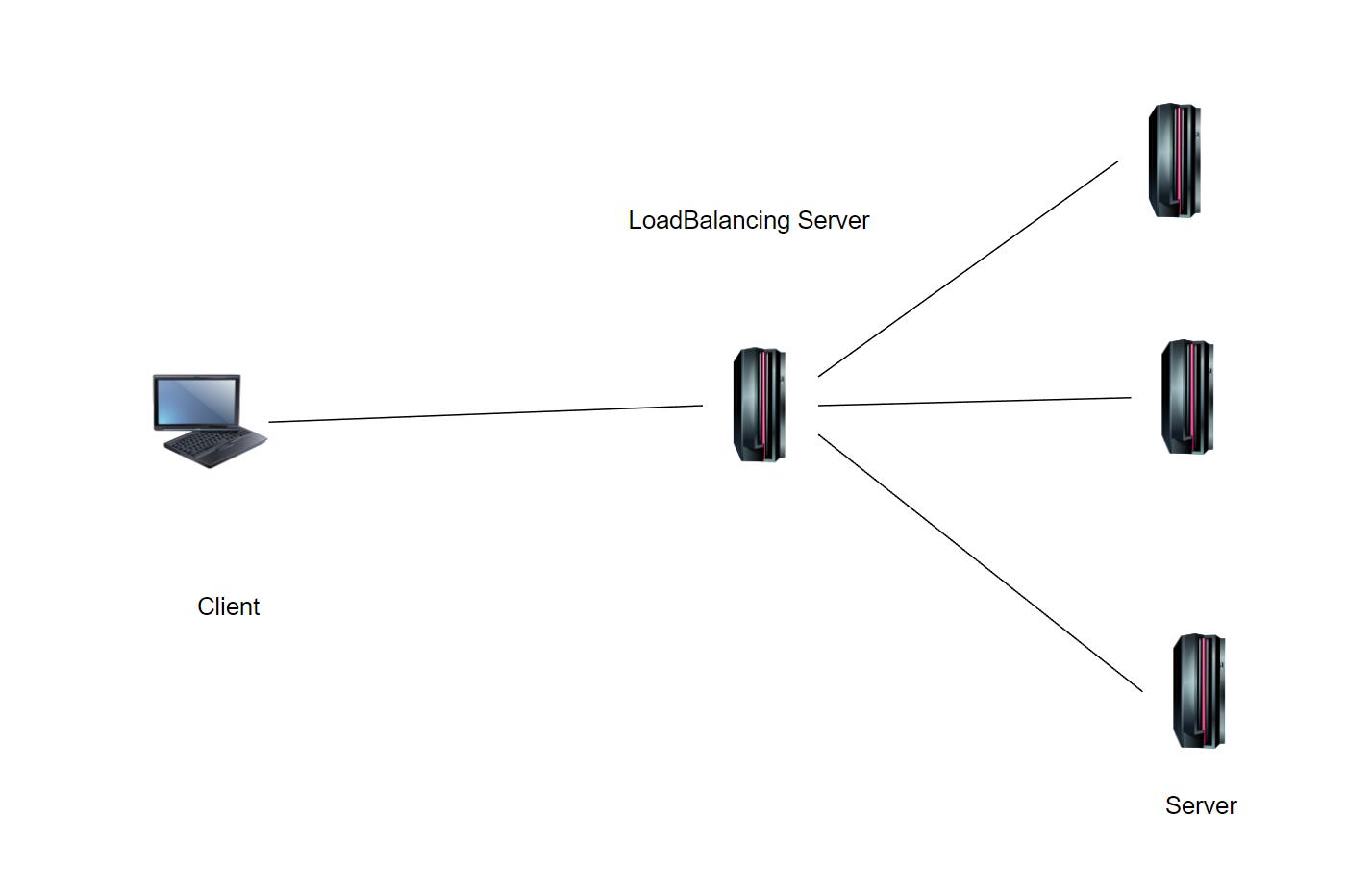
The direct connection deployment method is relatively simple, that is, the load balancing device is directly deployed on the path that packets must pass through. As a routing device between the server and the client, all incoming and outgoing packets are directly routed by the load balancing device. The deployment diagram is as shown below.
Deployment diagram of load balancing equipment in direct connection mode
- Side-mounted deployment method
The side-mounted deployment method of the load balancing device means that the load balancing device does not serve as a routing device between the server and the client, but only hangs side-by-side on a general routing device, for example, connect to a router or switch. its deployment diagram is shown below.
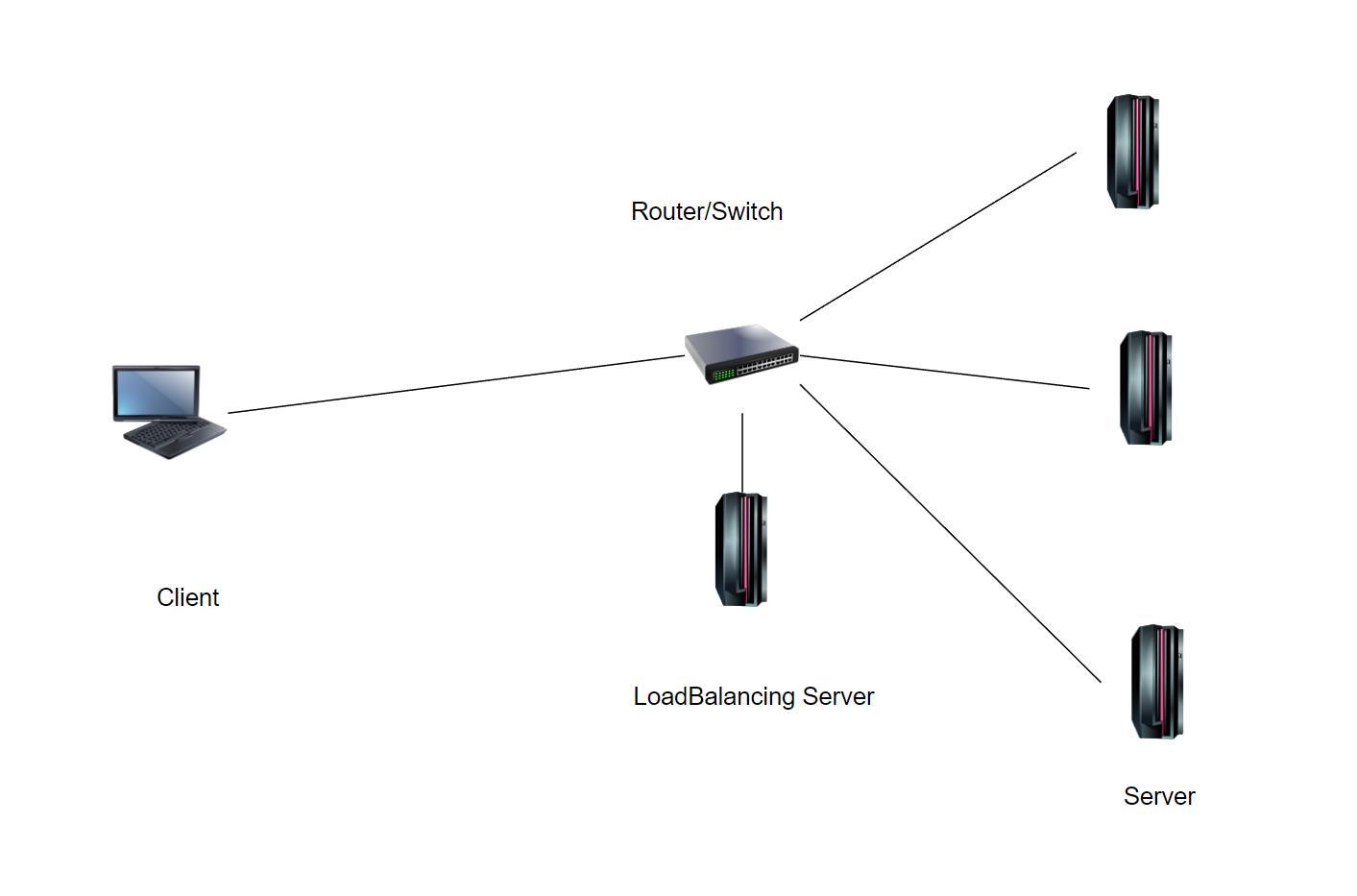
The configuration of the router or switch is very important, because if the request traffic sent by the client to the server is to be received by the load balancing device first, it must be in the routing Routing information to the virtual IP address of the load balancing device is pre-configured on the switching device.
In general, the traffic returned from the server to the client in the bypass deployment mode can be sent directly to the client through the routing and switching device without passing through the load balancing device. If you still want the traffic to return to the load balancing device first, some special steps are required, such as: make the server and the load balancing device in the same layer 2 network, set the server’s gateway as the load balancing device; configure the routing switching device The routing policy directs the traffic returned from the server to the load balancing device; the load balancing device performs source address NAT translation when forwarding client traffic. These processing operations are very important when the load balancing device needs to take on more functions (such as SSL acceleration).
Dual-machine hot standby deployment method
Regardless of whether it is deployed directly or side-by-side, the load balancing device is always on the critical path of the network, so the stability and security of the load balancing device directly affects the availability of the network. In order to avoid the single point of failure of the entire system caused by the failure of the load balancing device, the load balancing device must support dual-machine hot backup, that is, the business backup on the opposite device is performed through the backup link between the two load balancing devices to ensure that the two load balancing devices The service status of each device is always consistent. When one of the devices fails, business traffic can be switched to another device in time. Because another device has backed up all the business information on the failed device, business traffic can continue to be processed and distributed by the device, thus avoiding business interruption as much as possible.
There are two main types of dual-machine hot standby implementation of load balancing equipment: active-standby mode and load-sharing mode.
Master-backup mode: Among the two load balancing devices, one serves as the master device and the other serves as the backup device. The primary device is responsible for processing all services and transmits the generated business information to the backup device through the backup link. The backup device does not handle actual business, but is only used for backup. When the main device fails, the backup device promptly takes over the processing of services from the main device. While responsible for the normal processing of newly initiated load balancing services, it also ensures that previously ongoing load balancing services are not interrupted.
Load sharing mode: Both load balancing devices are master devices and can handle business traffic. At the same time, they serve as backup devices for each other and are responsible for backing up business information generated by the opposite device. When one of the devices fails, the other device will be responsible for processing all services. While responsible for processing the newly initiated load balancing services normally, it must also ensure that the previously ongoing load balancing services will not be interrupted.
Server load balancing
Server load balancing is a technology that distributes client requests evenly among servers in a cluster. According to the division of different layers located in the seven-layer network protocol stack, server load balancing can be divided into two types: layer four (L4) load balancing and layer seven (L7) load balancing. Among them, L4 load balancing is a flow-based server load balancing, which can distribute packets on a flow-by-flow basis, that is, distribute packets of the same flow to the same server; L7 load balancing is a content-based server load balancing, which can distribute messages across seven layers. The content of the message is deeply analyzed, forwarded packet by packet based on the keywords in it, and the connection is directed to the designated server according to the established policy. Comparing the two, L4 load balancing cannot achieve content-based distribution of seven-layer services, which limits its scope of application. Therefore, L7 load balancing has received great attention from the industry and has gradually become the mainstream of server load balancing.
Four-layer load balancing
There are two main types of L4 load balancing implementation: NAT method and DR method, which are suitable for different application scenarios.
NAT mode L4 load balancing
Network Address Translation (NAT, Network Address Translation) is a WAN access technology. It is a conversion technology that converts private (reserved) addresses into legal IP addresses. It is widely used in various types of Internet access methods and various types of in the network.
Using L4 server load balancing implemented by NAT, the back-end servers can be located in different physical locations and different LANs. When the load balancing device distributes service requests, it needs to translate the virtual IP address and the destination IP address, and then forward the packet to the server with the corresponding destination address through routing. below diagram shows the typical networking of NAT mode L4 load balancing.
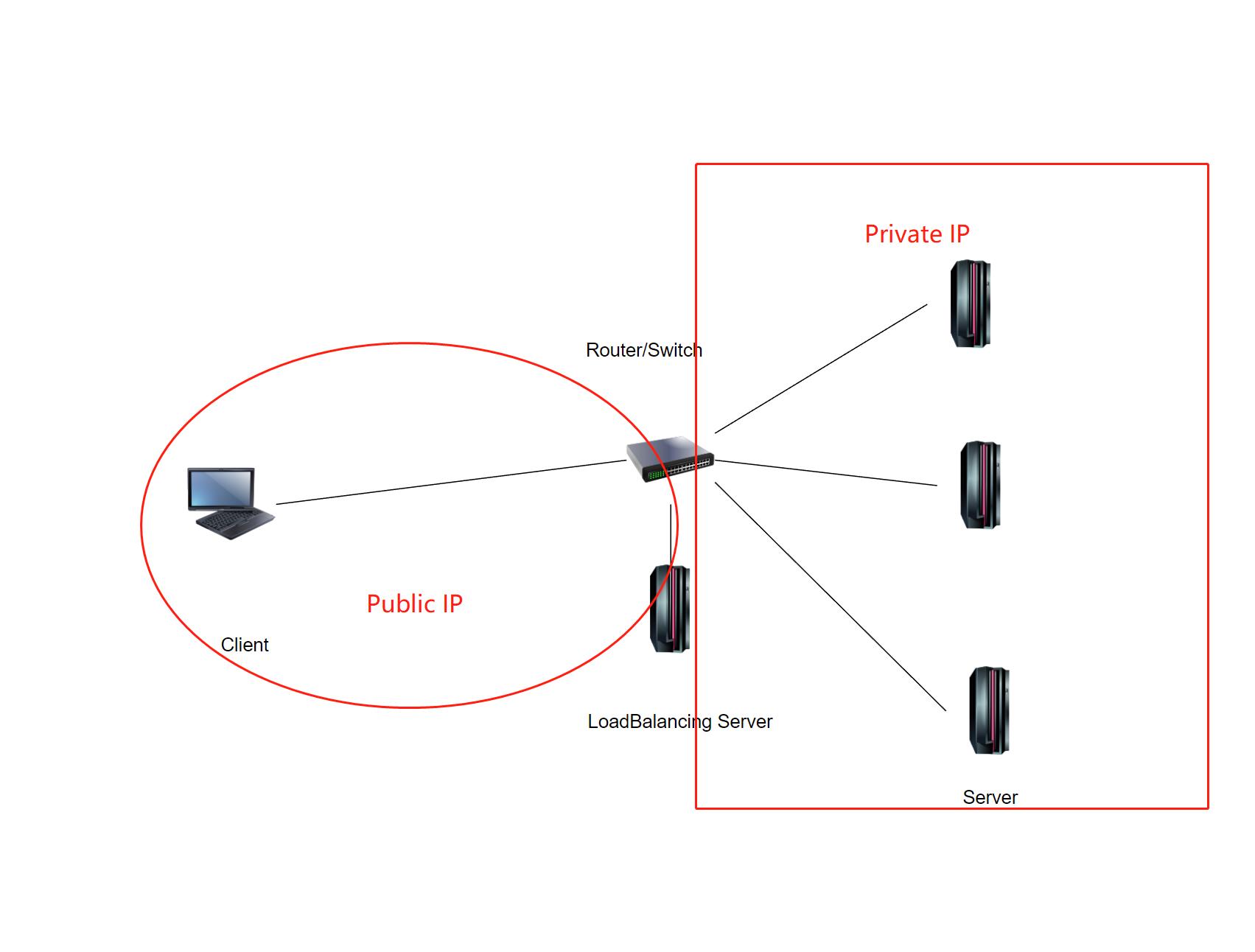
The main components in above diagram include the following.
- Load balancing device: Responsible for distributing client service requests to specific servers in the server cluster for processing.
- Real server: A server responsible for responding to and processing various client service requests. Multiple servers form a cluster.
- Virtual IP address: The public IP address provided by the cluster is used by clients when requesting services.
- Server IP address: The IP address of the server is used by the load balancing device when distributing service requests. This IP address can be a public IP or a private IP.
The working principle of NAT mode L4 server load balancing is shown below.
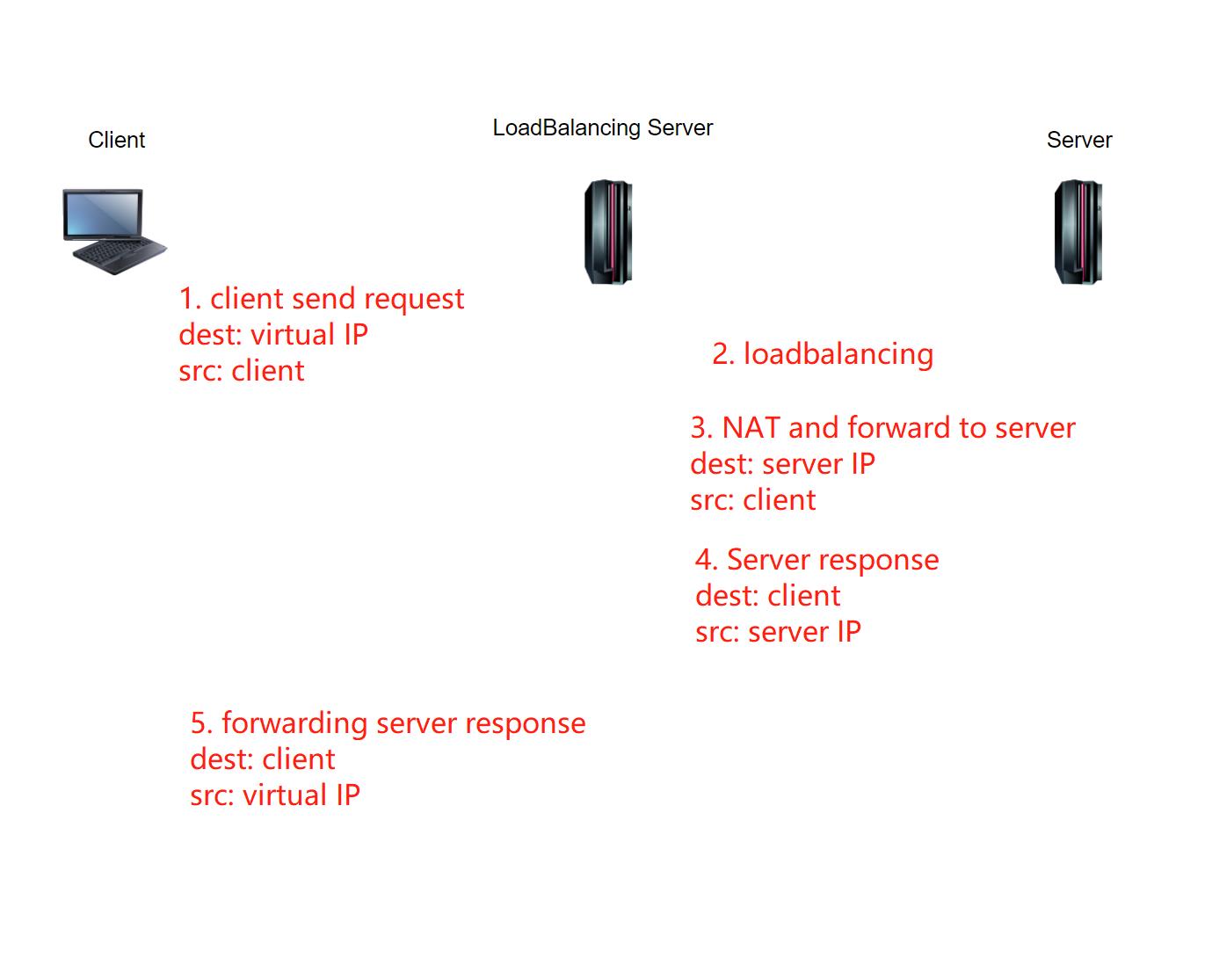
The workflow is like this:
The load balancing device is responsible for receiving service requests sent by the client to the virtual IP address.
The load balancing device schedules the load balancing algorithm through server availability verification, session persistence guarantee, etc., and selects the real server responsible for responding to and processing the request.
The load balancing device rewrites the destination address of the request message with the IP address of the real server, and then sends the request to the selected real server.
The response message of the real server first passes through the load balancing device.
The load balancing device modifies the source address of the response message to the virtual IP address, and then returns it to the client.
This method uses Network Address Translation (NAT) technology to achieve L4 load balancing. It has the characteristics of flexible networking and is suitable for a variety of networking types. This method has no additional requirements on the server and does not require modification of the server configuration.
DR mode L4 load balancing
DR (Direct Routing) is another implementation of L4 server load balancing. Different from the NAT mode of L4 load balancing, in the DR mode, only the service request messages sent by the client need to pass through the load balancing device, while the response messages sent by the server do not need to pass through. This can effectively reduce the load pressure on the load balancing device and avoid overloading. The balancing device becomes the system performance bottleneck.
In DR mode, when the load balancing device distributes server requests, it does not change the destination IP address of the request. Instead, it replaces the destination MAC address of the message with the MAC address of the server, and then directly forwards the message to the server.
The implementation scheme of L4 server load balancing in DR mode is similar to that in NAT mode. The difference is that the load balancing device is connected to the switch in a bypass mode, and each server in the cluster processes user requests. All have separate virtual IP addresses.
The principle of DR mode L4 load balancing is to configure virtual IP addresses for the load balancing device and the real server at the same time, but it requires that the virtual IP address of the real server cannot respond to ARP requests. For example, configure a virtual IP address on the loopback interface. In addition to the virtual IP address, the server used to respond to service requests also needs to be configured with a real IP address for communication with the load balancing device. The load balancing device must be in the same layer 2 network as the real server. Because the server’s virtual IP address cannot respond to ARP requests, the packets sent from the client to the virtual IP address will be received by the load balancing device, and the load balancing device will then distribute them to the corresponding real servers, and the packets sent from the real server to the client will The response message is returned directly by the switch. Below is the workflow:
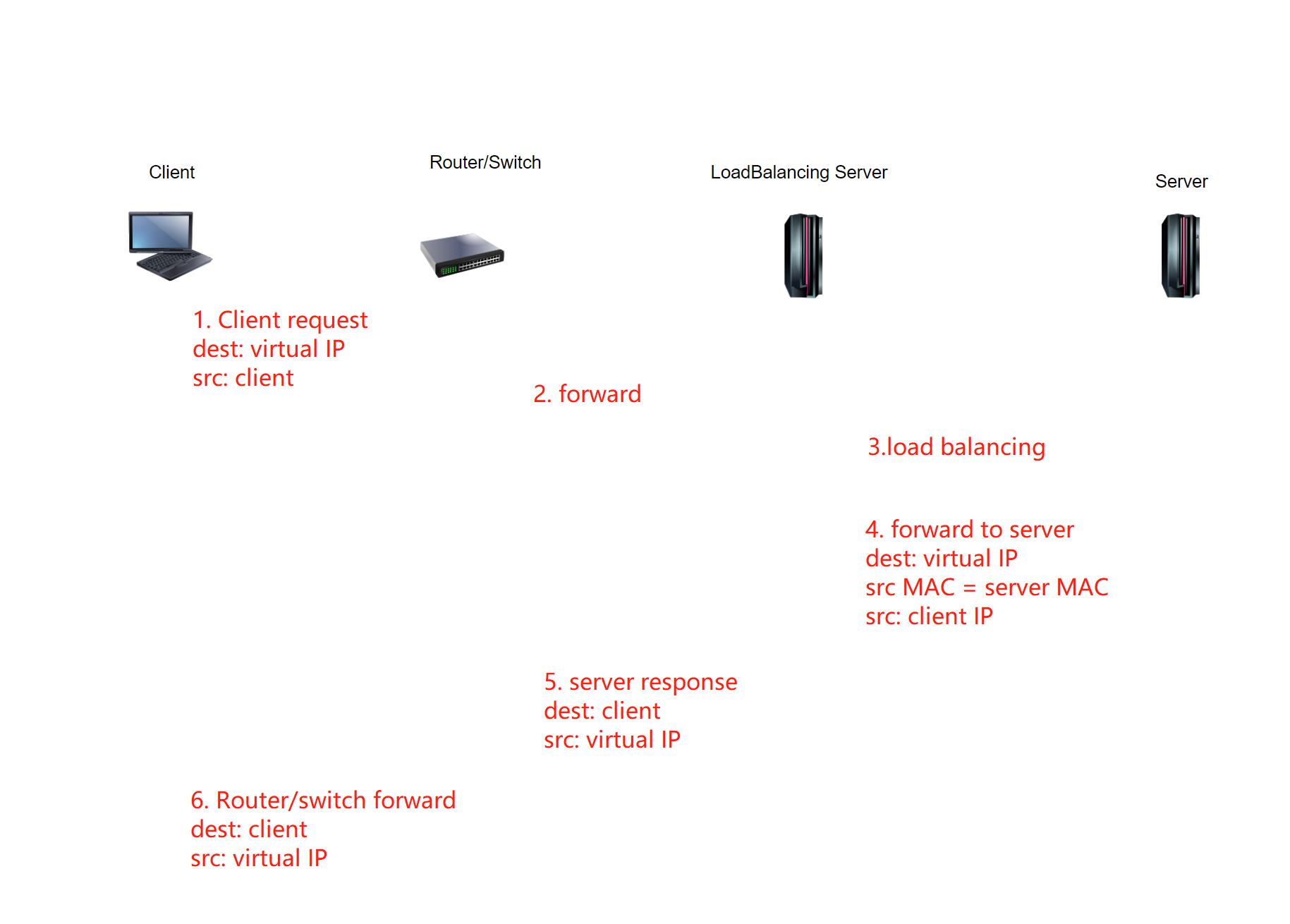
This method does not use the traditional forwarding method of looking up the routing table to distribute request messages, but directly routes it to the server by modifying the destination MAC. This is how the DR method gets its name. This method only requires one-way request messages from the client to the server to pass through the load balancing device. The load balancing device has a smaller burden, is less likely to become a bottleneck, and has higher processing performance.
Seven-layer load balancing
After L4 server load balancing intercepts the data flow, the inspection and analysis of the data packet is limited to the IP packet header and TCP/UDP packet header, and does not care about the payload information of the TCP/UDP packet. L7 server load balancing requires that in addition to supporting load balancing based on four layers, the load balancing device must also parse information above four layers in the data packet, that is, application layer information, such as parsing HTTP content to extract information from the data packet. HTTP URL or Cookie information is used as the basis for load balancing.
L7 server load balancing controls application layer service distribution through content analysis, providing a high-level access traffic control method. Compared with the previous traditional L4 load balancing, L7 load balancing has the following advantages.
Able to direct data traffic to a server that can handle the corresponding content based on the content of the data packet (for example, determining whether the data packet is an image file, compressed file, or multimedia file, etc.) to improve system manageability and flexibility.
Able to direct the request to the corresponding server for processing based on the data type of the connection request (for example, based on the URL, determine whether the request sent by the user is related to static documents such as ordinary text, images, etc., or to dynamic documents such as ASP, CGI, etc.) , which helps improve security while improving system performance.
It can ensure session persistence based on the application layer load, which is more refined than the address-based persistence guarantee method used by L4 server load balancing.
L7 server load balancing is very similar to NAT L4 server load balancing in implementation. The main difference is the addition of the concept of service groups. Service group is a logical concept that divides multiple servers into different groups based on some common attributes. For example, servers can be divided into static data storage server groups and dynamic exchange server groups, or into music server groups, video server groups, picture server groups, etc. Each server within a server group divided according to application layer attributes is more likely to have similar performance and features.
Below diagram demonstrates how L7 server load balancing works.

Establish a TCP connection between the client and the load balancing device located at the front end of the server cluster.
The client sends the service request sent to the virtual IP address to the load balancing device, and the load balancing device receives the client request.
The load balancing device selects the real server responsible for responding to and processing the request through steps such as server availability verification, session persistence guarantee, service group matching strategy, and load balancing algorithm scheduling.
The load balancing device uses the client address to establish a TCP connection with the real server.
The load balancing device rewrites the destination address of the client request message to the IP address of the real server, and sends the request to the corresponding server.
The real server responds to the load balancing device with services.
When the packet passes through the load balancing device, the source address is restored to the virtual IP address and then returned to the client.
L7 server load balancing can deeply identify application layer protocols during the load balancing process, which brings many more refined balancing possibilities. However, it also places very high requirements on system performance, which usually requires the use of dedicated chips and hardware circuits. way to achieve. At the same time, it requires a corresponding independent identification mechanism for each application layer protocol, which greatly limits the application scalability of L7 server load balancing. Since the HTTP protocol is widely used and the protocol is relatively simple, the current L7 load balancing technology has the strongest commercial ability to load balance HTTP requests.
It should also be noted that in actual applications, L4 load balancing and L7 load balancing are often used together. Of course, it is best to have both layer four and layer seven functions on the same load balancing device. The load balancing device first extracts the IP address and port number from the message and performs Layer 4 load balancing. If it is found that further forwarding based on the message content is necessary, it then implements Layer 7 load balancing operation.
Link load balancing
We learned about server load balancing earlier. Next, we will introduce a type of load balancing called link load balancing. This refers to load balancing across multiple network links through dynamic algorithms.
In order to avoid network availability risks caused by operator network exit failures and solve problems such as network access failure caused by insufficient network bandwidth, enterprise users usually rent two or more operator networks at the same time. In this case, the question is how to rationally use the network exits of these multiple operators. Traditional policy-based routing can solve the problem to a certain extent, but it is inconvenient to configure and difficult to dynamically adapt to network architecture changes. The most important thing is that this method cannot dynamically adjust packet distribution according to the actual bandwidth usage, resulting in a waste of idle link throughput capacity. Therefore, link load balancing was proposed, hoping to solve a series of problems existing in traditional routing technology.
Link load balancing can be divided into two situations: outbound link load balancing and inbound link load balancing according to the direction of business traffic. Among them, Outbound link load balancing mainly solves the problem of how to dynamically allocate and load balance among multiple different links when the enterprise’s internal business system accesses external Internet services; Inbound link load balancing mainly solves the problem of how to dynamically allocate and load balance among multiple different links when the enterprise’s internal business system accesses external Internet services. How users can dynamically balance the distribution on multiple links when accessing corporate internal websites and business systems, and intelligently and automatically switch to another available link when one link is interrupted.
The main difference between link load balancing and server load balancing is that the objects that bear the load are different. As far as the load balancing equipment is concerned, its key technologies, deployment methods and other contents are similar. Among them, in terms of load balancing scheduling algorithms, link load balancing has some unique algorithms, such as nearest link selection algorithm, link bandwidth-based scheduling algorithm, etc. In particular, the nearest link selection algorithm can detect the status of the link in real time during the link load balancing process, and select the optimal link based on the detection results to ensure that traffic is forwarded through the optimal link. The nearest link selection algorithm can detect link status through link health detection, such as sending DNS messages and ICMP messages, establishing TCP half-open connections, etc. to verify link reachability and obtain relevant information at the same time. Nearest link calculation parameters. In the implementation, the nearby link calculation parameters mainly include: link physical bandwidth, link cost (such as monthly link rental), link delay time, routing hop count, etc. The nearest link selection algorithm can also perform weighted calculations based on these parameters, and then determine the quality of the link based on the calculation results.
-[] Outbound link load balancing
not too much to discuss in this section
When there are multiple links between the internal network and the external network, Outbound link load balancing can realize the function of sharing the traffic of internal network users accessing external network servers on multiple links.
Load balancing device: Responsible for distributing traffic from the internal network to the external network across multiple physical links.
Physical link: The actual communication link provided by the network server provider (ISP).
Virtual IP address: The virtual IP address provided by the load balancing device is used as the destination address of the packets sent by the user.
The principle of outbound link load balancing is to use the virtual IP address of the load balancing device as the destination address of packets sent by intranet users. After the user sends the packet accessing the virtual IP address to the load balancing device, the load balancing device selects the best physical link through the link selection algorithm and distributes the business traffic from the internal network to the external network to the link.
The technical features of outbound link load balancing include the following.
By combining NAT technology for networking, different links use different source IP addresses, thus ensuring that all round-trip packets pass through the same link.
Through health detection, the connectivity of any node on the link can be detected, thereby effectively ensuring the reachability of the entire path.
Through the scheduling of load balancing scheduling algorithms, traffic can be balanced among multiple links, such as using bandwidth-based algorithms to optimize bandwidth utilization and using nearby link selection algorithms to select the optimal link.
-[] Inbound link load balancing
For detail information check CDN_Notes.
As mentioned earlier, the main function of Inbound link load balancing is to evenly schedule the traffic of external network users accessing the company’s internal websites and business systems on multiple links, and to intelligently and automatically switch to another link when one link is interrupted. Available links.
Although the implementation of Inbound link load balancing is similar to Outbound link load balancing in many aspects, because it targets business traffic in different transmission directions, some functions have the following points:
Load balancing device: Responsible for guiding external network traffic to be forwarded to the internal network through different physical links to achieve distribution of traffic on multiple physical links. At the same time, the load balancing device also needs to serve as the authoritative name server for the domain name to be resolved.
Physical link: The actual communication link provided by the network server provider (ISP).
Local DNS server: Responsible for processing DNS resolution requests sent by local users and forwarding the requests to the load balancing device as the authoritative name server.
The principle of inbound link load balancing is to use the load balancing device as an authoritative name server to record the mapping relationship between the domain name and the IP address of the intranet server (that is, the A record of the domain name). In Chapter 5 of this book, we will learn that a domain name will be mapped to multiple IP addresses, and each IP address corresponds to a physical link. When an external network user accesses an intranet server through a domain name, the local DNS server will request domain name resolution from the load balancing device according to the recursive principle. The load balancing device will select the best physical server through steps such as nearest link selection algorithm screening and ISP selection. link, and feeds back the IP address of the interface connected to the external network through the link to the external network user as the DNS domain name resolution result.
Inbound link load balancing cooperates with server load balancing to achieve balancing among multiple links and balancing among multiple servers at the same time. Another application method is to use a dynamic link selection algorithm to ultimately achieve server load balancing based on link optimization.
Open source load balancing software
Currently, there are many mature systems and software in the industry used to achieve cluster load balancing. The most widely used ones include LVS, which is mainly used to achieve four-layer load balancing, and Nginx, which is mainly used to achieve seven-layer load balancing. They are both Load balancing software developed with the support of the open source community.
LVS
LVS (Linux Virtual Server) is an open source software project under the GPL license initiated by Zhang Wensong of the University of Defense Technology in May 1998. Its goal is to develop high-performance, high-availability load balancing solutions for Linux cluster systems. Currently, LVS has become part of the Linux standard kernel. The various modules of LVS have been fully built into the Linux kernel after version 2.4, and users can directly use various functions provided by LVS. Since the inception of the project, LVS has developed into a very mature technology project that can be used to provide highly scalable, highly reliable, and highly serviceable Linux cluster system services. Many well-known websites and organizations have used LVS technology. , For example: Linux portal website, Real company that provides audio and video services to RealPlayer, the world’s largest open source website SourceForge, etc.
The load balancing system is usually located at the front end of the entire cluster and consists of one or more load schedulers. LVS is installed and deployed on the load balancing scheduler. The main function of the installed LVS load scheduler is similar to a router. It contains the routing table required to complete the LVS load balancing function, and distributes user requests to the application servers in the cluster through the routing information. At the same time, the LVS load scheduler also needs to monitor the working status of each application server and update the LVS routing table at any time based on whether the server status is normal and available.
The core of LVS is IP load balancing. The IPVS module that implements this function is installed on the load scheduler and virtualizes an IP address to provide to users. Users must use this virtual IP address to access the application services provided by the cluster. , that is, all user requests first reach the load scheduler via the virtual IP address, and then the load scheduler will select a suitable node from the application server list to respond to the user request. Based on the differences in the way the scheduler sends requests to the application server node and the application server returns data to the user, IPVS has different implementation methods such as NAT (Network Address Translation), TUN (IP Tunneling), and DR (Direct Routing). Among them, in addition to the NAT and DR methods introduced in this book, TUN refers to the technology of encapsulating one IP packet in another IP packet. IPVS uses this technology to first encapsulate the user request and then forward it to the application server. The response The content is returned directly from the application server to the user. Using the TUN method, the LVS load scheduler is only responsible for scheduling user requests and does not process response data. It only consumes the overhead of establishing IP tunnels and has higher performance. However, the implementation of TUN technology has higher requirements on the server, that is, all The server must support the “IP Tunneling” or “IP Encapsulation” protocol. In addition, LVS can provide a variety of load balancing scheduling algorithms, such as Round Robin, Weighted Round Robin, Least Connection, Weighted Least Connection, etc.
The main features of LVS include the following.
Good performance. LVS is integrated into the operating system kernel and distributes user requests at the fourth layer of the network protocol stack. It does not generate traffic itself, so it has extremely high performance.
Simple configuration. LVS has been supported by the majority of Linux and FreeBSD operating systems. The configuration file is relatively simple and easy to operate, which reduces the chance of configuration errors.
Stable work. LVS has been widely proven to be extremely reliable in practical applications, and it has a complete dual-machine hot backup solution, such as LVS+Keepalived and LVS+Heartbeat.
Currently, in addition to IP load balancing, LVS also implements KTCPVS (Kernel TCP Virtual Server) for load balancing operations at the seventh layer of the network protocol stack, as well as some other extended function modules. The official website of LVS is http://www.linuxvirtualserver.org. The website provides download links for the latest version of LVS and related software manuals.
Nginx
Nginx (pronounced engine-x) is a high-performance HTTP and reverse proxy server, as well as an IMAP/POP3/SMTP proxy server. Nginx was developed by Russian Igor Sysoev in 2002. It follows a 2-clause BSD-like license and its first public version 0.1.0 was released on October 4, 2004. On November 15, 2011, the stable version 1.0.10 of Nginx was officially released. Nginx has very superior performance, especially extremely high concurrent processing capabilities, so it has been favored by many Internet websites. According to the statistical report of the Internet monitoring company Netcraft, as of November 2011, it is among the 1 million busiest Web sites in the world. 8.01% of the share uses Nginx software, including WordPress, Hulu, Github, Ohloh, SourceForge, WhitePages, TorrentReactor, etc.
Nginx (pronounced engine-x) is a high-performance HTTP and reverse proxy server, as well as an IMAP/POP3/SMTP proxy server. Nginx was developed by Russian Igor Sysoev in 2002. It follows a 2-clause BSD-like license and its first public version 0.1.0 was released on October 4, 2004. On November 15, 2011, the stable version 1.0.10 of Nginx was officially released. Nginx has very superior performance, especially extremely high concurrent processing capabilities, so it has been favored by many Internet websites. According to the statistical report of the Internet monitoring company Netcraft, as of November 2011, it is among the 1 million busiest Web sites in the world. 8.01% of the share uses Nginx software, including WordPress, Hulu, Github, Ohloh, SourceForge, WhitePages, TorrentReactor, etc.
Nginx implements a complete HTTP server function. In actual website deployment, it is often used to handle the load balancing problem of the seven layers of the network protocol stack. The core of Nginx load balancing is the Upstream module. When Nginx receives an HTTP request from a user, it will create an Upstream request to the back-end application server. After the application server sends back the response data, Nginx will then upload the back-end Upstream request to the back-end application server. The data is forwarded to the user. The load scheduling algorithms supported by Upstream mainly include Hash based on source IP, Hash based on destination URL, fair scheduling based on response time, etc.
The main features of Nginx include the following points.
Flexible scheduling. Nginx works on the seventh layer of the network protocol stack, can parse and offload HTTP application requests, supports more complex regular rules, and has a more optimized load scheduling effect.
Low network dependence. Nginx has very little dependence on the network. In theory, load balancing can be implemented as long as it can be pinged, and it can effectively distinguish between intranet and external network traffic.
Support server detection. Nginx can detect whether the server fails based on the status code and timeout information returned by the application server when processing the page, and promptly resubmits the request that returns an error to other nodes.
Compared with LVS, Nginx is mainly used for the scheduling of the seventh layer of the network. It has more advantages in flexibility and effectiveness. At the same time, its detection of server health status also avoids disconnection during user access. However, the complexity of network layer seven information processing also makes Nginx have a large gap compared with LVS in terms of load capacity and stability. In addition, it currently only supports HTTP applications and EMAIL applications. It is not as rich in application scenarios as LVS, and it does not have a ready-made dual-machine hot backup solution. Overall, the combined use of LVS and Nginx can be considered in actual scenarios. LVS is deployed on the front end to handle four-layer load balancing. When more detailed load scheduling is required, Nginx is enabled to optimize the scheduling effect.
Nginx website: https://www.nginx.com/